
Multi object tracking research trends
Published:
Multiple object tracking approaches…
Tracking objects from video become one of the extensively studied research with the advent of artificial intelligence. The problem is divided into two parts: detection of object in each video frame and association of the same object over time to make the tracking happen.
Tracking = Detection + Association
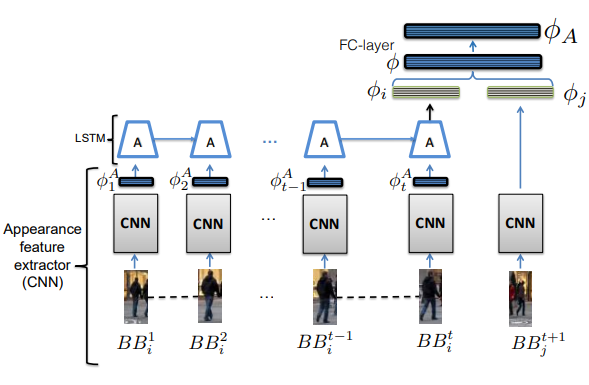
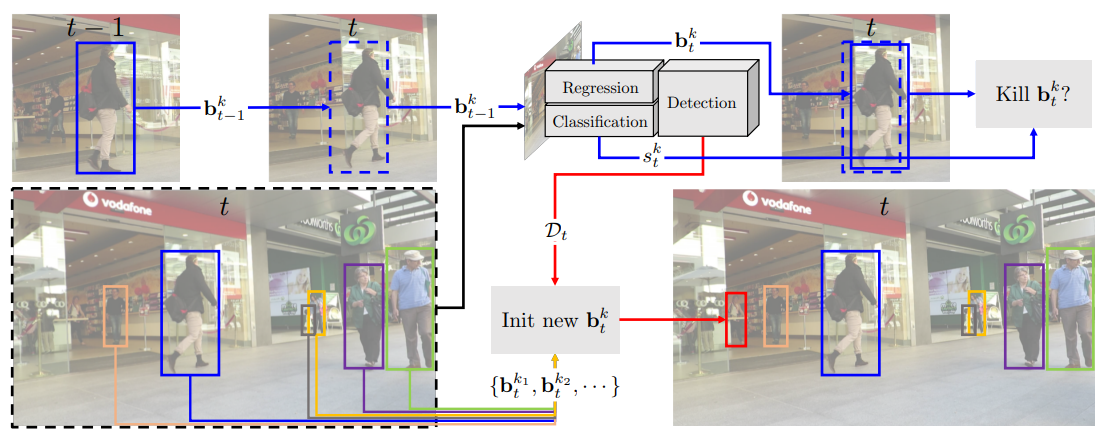
An association algorithm (most commonly hungraian algorithm) associate each object in consecutive frames. To conduct association over frames for an individual object different cues are considered to match, like appearance , motion, pose etc.
There are two types of tracking approaches: 1. Top-down approach, 2. Bottom-up approach. Top-down approaches detect the bounding box first and then associate bounding boxes in consecutive frames. Bottom-up approach use more granular cue to detect and associate objects over frames. In particular, it uses pose or pixel cue for association.
I have enlisted few papers from both approaches.
Top-down tracking approaches:
- Paper 1:- Tracking The Untrackable: Learning to Track Multiple Cues with Long-Term Dependencies link.
- Paper 2:- Tracking without bells and whistles link.
Bottom-up tracking approaches:
- Paper 3:- PoseTrack: Joint Multi-Person Pose Estimation and Tracking link.
- Paper 4:- Simple Baselines for Human Pose Estimation and Tracking link.

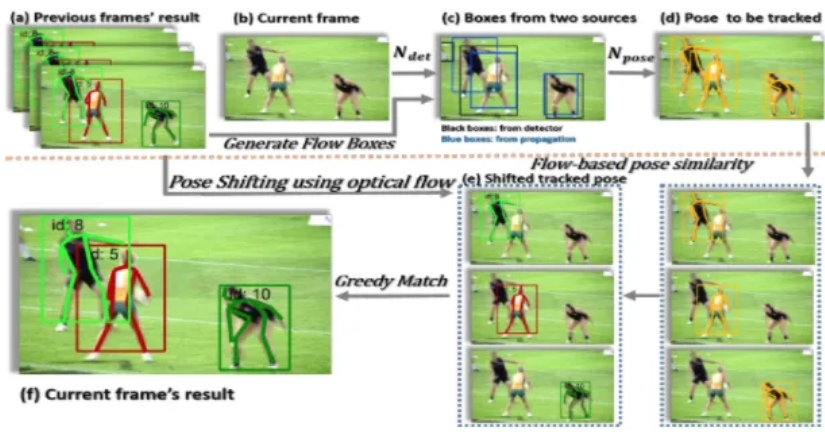
Conclusion: Bottom-up approach matching is computationally expensive as matching need to be done with many keypoints of multiple objects over time. Therefore, its difficult to get feasible solution from bottom approach. On the other hand, top down approaches associate objects using detected bounding boxes which is faster to optimize even using simple hungarian algorithm.